


0
온라인133
사용자22.0k
토픽22.2k
게시물-
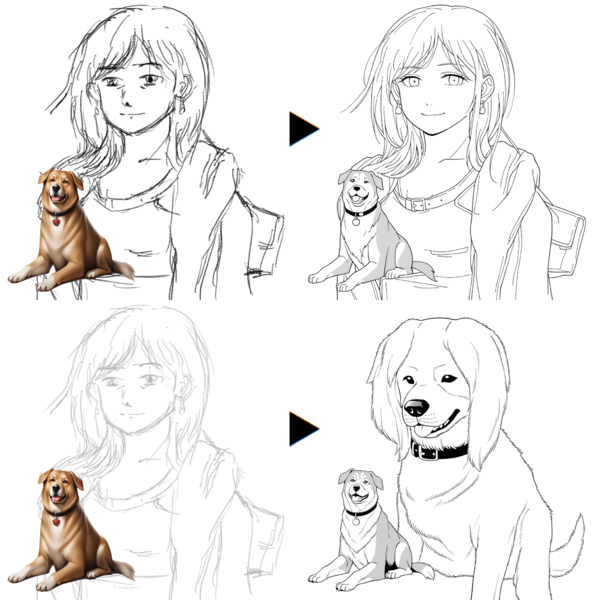
필자의 거친 그림 (왼쪽)에서 copainter를 사용하여 펜 넣기 (중앙), 착채 (오른쪽)
일본의 AI 스타트업, 라디우스 파이브가 제공하고 있는 AI 착채 서비스 「copainter(코페인터)」에 새롭게 도입된 「펜 넣기」기능의 성능이 굉장히 높습니다. 러프화 등으로부터 선화를 생성한다고 하는, 지금까지 화상 생성 AI의 「Stable Diffusion」으로 실현되고 있었던 것의 연장선상에 있는 기능입니다만, 그것을 서비스로서 품질 높게 정리한 느낌입니다. UI가 어쨌든 심플하고, 생성 AI를 모르는 사람이라도 헤매지 않고 이용할 수 있는 알기 쉬운 만들기가 되어 있었습니다.
펜 넣기와 색채가 1분으로 끝난다
copainter의 기능은, 기존 화상을 선화화하는 「펜 넣기」와, 지정에 맞추어 색을 붙이는 「착채」의 2개입니다.사용 방법은 선화로 하고 싶은 화상을 드롭하면, 충실도/선의 굵기/입감의 파라미터를 조정해, 버튼을 누르기만 하면 됩니다. 1분 정도로 선화가 나옵니다. 다음은 「착채」. 이 때에도 채우기의 참고가 되는 이미지를 선택하고 버튼을 누르기만 하면 됩니다. 낙서한 것으로 나오는 것인지를 시도해 보았습니다. 필자가 그린 낙서가 1분 정도로 이렇게 됩니다.

필자가 내일 내코씨의 이미지를 모사한 것(왼쪽)을 copaniter로 「펜 넣어」를 한 것(오른쪽). 원래 모호한 선에서 잘 모양을 만들어 준다.

동일한 이미지를 입력하더라도 생성 결과는 충실도를 변경하면 상당히 변합니다. 왼쪽부터 충실도 0.05, 충실도 0.5, 충실도 0.9
선화를 간단하게 착채(중앙)로 하고, 선화와 밑칠 화상을, 입력 정보로서 「착채」한 결과(오른쪽). 약간 청색 기미에 색이 붙는 경향이 있는 것은 사용 모델의 특성이라고 생각된다. 색채도 파라미터 설정에 의해 상당히 결과가 바뀐다어떤 이미지라도 선화 할 수 있기 때문에 3D 이미지 등에도 사용할 수 있습니다. 예를 들어, 3D 모델의 VRoid 샘플 모델의 스크린 샷을 사용하고 펜 넣은 후 원래 스크린 샷을 밑칠 이미지로 지정하면 일러스트 스타일로 그려진 이미지를 만들 수 있습니다.

VRoid 스크린샷(왼쪽), 펜 넣기(가운데), 채색(오른쪽)필자가 개발하고 있는 게임 「Exelio(엑셀리오)」에 등장하는 「수수께끼의 개구리」캐릭터에서도 시험해 보았습니다. 개구리와 메카의 요소를 과도하게 해석해 버린 것 같아, 펜 넣기 단계에서 생물적인 분위기가 감소해, 메카적인 의장이 추가되고 있습니다. 그 분위기는 착채에서도 계승되어 있기 때문에, 원래의 이미지에 가까운 이미지로 하기 위해서는 여러가지 궁리가 필요할 것 같습니다.

필자가 개발중인 게임 "Exelio (엑셀리오)"에 등장하는 캐릭터의 스크린 샷 (왼쪽), 펜 넣어 (중앙), 착채 (오른쪽)메일 등록만으로 월에 10회까지 무료로 시도할 수 있다는 것도 있어, X상에서는 다양한 사람이 시도한 것이 투고되고 있습니다. 프로의 밑그림은, 훌륭하게 착채까지 성공하고 있습니다.
중학생 무렵에 그린 그림이 '보물의 산'이 되었다고 쓰는 사람도 있습니다. 사용되고 있는 생성 AI 모델의 특성으로, 눈의 형상이 바뀌거나 하고 있는 것도 있습니다만, 수정을 전제로 한다면, 충분히 프로 수준에서도 사용물이 된다고 하는 평가를 얻고 있는 인상입니다.
이미지를 분석하는 "태그 생성"단계가 포함되어 있다고 생각됩니다.
copainter가 하고 있는 것은, 이미지 생성 AI 「Stable Diffusion」을 사용한 image2image(i2i)라고 생각됩니다. i2i에서 이미지를 선화하는 방법은 LoRA(추가 학습 기능)가 본격적으로 보급되어 온 2023년 초기부터 존재하고 있었습니다.다만, 완전한 선화로 하거나, 화풍을 원화상에 가까운 것으로 하는 것이 어려웠거나, 컨트롤면에 과제를 안고 있었습니다. 또, 밑그림과 같은 것을 깨끗하게 정돈하는 것은 간단하지 않았습니다. 얼굴이 바뀌어 버리거나, 좋은 것이 다양하게 들어 버리거나. 그것이 copainter에서 상당히 조정되었으며 가능한 한 원본 이미지를 활용하기 위해 버릇이없는 출력 결과가되도록 조정되어 감동합니다.
덧붙여 copainter는 「개의 이미지를 넣으면 파탄한다」라고 하는 소문이 있었습니다. 왜 그런 일이 일어나는지는 기술 정보가 공개되어 있지 않기 때문에 약간의 추측이 들어갑니다만, 생성 순서를 이해하면 알 수 있습니다.
첫째, 이미지를 생성하기 전에 이미지를 분석하여 무엇이 그려지는지를 결정하는 "태그 생성"단계가 포함되어 있다고 생각됩니다. 이 태그 해석의 방법은 데이터가 오픈화되어 있어 이미지 생성용의 앱 「Stable Diffusion WebUI A1111」에서도 확장 기능으로서 이용 가능합니다. 이 태그 정보를 프롬프트로 사용하면 생성 된 이미지의 정확도가 높아집니다. 생성된 이미지에서 예상하지 못한 저작권이 생성되었다는 보고가 나오지 않았기 때문에 저작권 태그가 생성되지 않도록 조정된 것으로 간주됩니다.
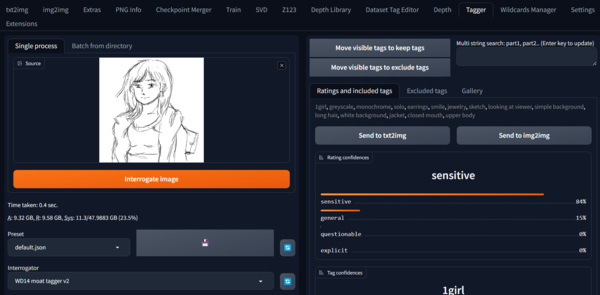
A1111의 확장 기능으로 필자의 모사를 태그 해석한 예. "1소녀, 그레이스케일, 흑백, 솔로, 귀걸이, 미소, 보석, 스케치, 보는 사람 보기, 간단한 배경, 긴 머리, 흰색 배경, 재킷, 닫힌 입, 상체"(해석 후 프롬프트 번역)파탄하는 경우입니다만, 원이 되는 화상에 태그 첨부를 붙이는 타이밍에서, 「개」라고 인식하면서, 「여성」이라고 인식할 수 없고, 프롬프트에 인간이 들어가지 않은 것 같은 경우에 일어납니다. 다만, 필자도 같은 이미지를 작성해 시험해 보았습니다만, 태그 해석을 돌파하는 것은 꽤 어렵고, 원화상의 캐릭터의 불투명도를 30%로 해서 처음으로 성공했습니다. 같은 이미지를 A1111에 넣어 태그를 해석해 보면, 여성 캐릭터가 존재하는 것을 인식할 수 없는 것을 확인할 수 있습니다.
개의 이미지를 추가하고, 펜 넣기를 해 본 것. 위는 보통 그대로, 아래는 캐릭터를 불투명도 30%로 설정해 본 것. 왼쪽 아래는 선이 얇기 때문에 인물이 인식할 수 없고 개가 생성되고 있다. A1111에서 태그 해석을 하면 「개, 인간 없음, 솔로, 간단한 배경, 흰색 배경, 혀, 목걸이, 쥬얼리, 동물, 보는 사람을 본다, 모노크롬」(번역)이 되었다즉, 배경색을 의도적으로 얇게 하는 등 '개'의 요소를 극단적으로 강조하는 등 드문 경우가 아니면 어려울 것이라고 생각되었습니다. 원래 이미지가 무엇을 의도하고 있는지 알기 어려운 이미지를 로드하지 않으면 적절한 태그가 붙지 않거나 수수께끼 개구리 케이스처럼 의도하는 것과는 다른 이미지가 됩니다. 이것은 화상 생성 AI의 특성이기도 하고, 파탄을 목표로 한 이용을 상정한 설계가 되어 있지 않기 때문에 일어나는 것입니다.
덧붙여서 요금 플랜은 월액 680엔의 라이트 플랜으로는 50회분 티켓입니다만, 전혀 부족합니다.
이미지 생성 AI를 이용하면, 1회로 베스트인 이미지가 나오는 것은 적고, 조금씩 파라미터 바꾸어 시행착오를 해, 최상의 결과를 찾는 것이 보통입니다. 게다가 착채도 똑같이 시험하게 되므로, 1장의 뛰어난 결과를 내기 위해서 6장 정도를 사용하게 됩니다. 페이지수가 있는 만화를 그린다고 하는 목적으로, 본격적으로 사용하려면 월액 1980엔의 300회분 티켓은 곧 필요하게 될 것입니다.
023년부터 진화해 온 「복사기 LoRA」
LoRA를 밑그림의 선화화라고 하는 특정 기능에 짜서 이용한다고 하는 방법론은, 2023년의 여름에 개발자의 츠키스와 나하씨가 발견한 「복사기 LoRA 학습법」 에 의한 극적인 진보가 있었습니다 .일반적으로는 LoRA라고 하면, 20~50장 정도의 유사한 화상을 학습시키는 것으로 특정의 도안을 낼 수 있게 하는, 추가 학습 방식을 가리킵니다. 그러나 복사기 LoRA의 학습 방법은 이질적입니다. 먼저 학습할 이미지를 2장으로 짜내고 각각 1장을 LoRA로 1000회 학습함으로써 극단적인 과학을 일으키는 2개의 LoRA를 만듭니다. 그리고 그것을 하나의 LoRA에 결합하면, 2장의 도안의 차이가 화상에 반영된다고 하는 방법을 취하고 있습니다 의 데이터에 대한 예측 정밀도를 저하시키는 현상).
예를 들어, 같은 그림의 컬러 화상과 흑백 화상으로 「복사기 LoRA」를 작성하면, 그 LoRA는 화상을 흑백화할 수 있는 성질을 가진 특정 기능 LoRA가 된다고 하는 것입니다.
이 방법이 발견됨으로써 특수효과 LoRA의 개발이 진행되었습니다. 복사기 LoRA는 학습 시간이 짧다는 이점도 있습니다. 기존의 LoRA의 경우, NVIDIA RTX 4090 환경에서도 100회 정도의 학습에 2~20시간이 걸리지만, 복사기 LoRA는 1000회의 훈련에서도 매수가 적기 때문에 30분 정도입니다. 원래 특정 기능을 생성하기 위해서는 많은 수의 학습 이미지를 준비 할 필요가 없다는 장점도 있습니다.

츠키스와・나나씨의 note 보다츠키스와씨는 이 기법을 사용해, 다양한 특수 기능 LoRA의 개발을 하고 있습니다. 특히 흥미로운 것이, 화면의 정보량을 컨트롤 할 수 있는 「Flat」. 이것을 플러스로 하면 화면은 평면인 화상이 되고, 마이너스로 하면 화면내에의 기입이 증가합니다. copainter를 채색할 때의 "쓰기 양" 파라미터는 Flat과 유사한 LoRA를 사용하여 제어하는 것으로 생각됩니다. 그 밖에도 윤곽선을 강조하거나 눈 크기를 변경하거나 입 모양을 제어하거나 전신을 금색으로 바꾸는 등 20~30종류의 다양한 특수 효과 LoRA를 개발하여 공개되었습니다.

츠키스와 나하 씨의 Flat Lora를 사용해 i2i로 화상의 효과를 시험한 곳. 중앙을 원화상으로 하고, 왼쪽이 「-1」(정보가 증가한다), 오른쪽이 「+1」(정보가 감소한다)복사기 LoRA 학습법에 관련해, 토리니쿠씨가 6월 23일에 발표한 것이, 「CoppyLora_webUI」( pixivFanbox로 유상 한정 공개 ). 이것은 복사기 LoRA 학습법을 손쉽게 취급할 수 있도록 한 앱입니다. 이 앱을 사용하면 특수 기능 LoRA와 그 사람의 도안 LoRA를 쉽게 만들 수 있습니다. 기본 모델 이미지를 가공하거나 모사하여 학습함으로써 LoRA에 특정한 특성을 부여할 수 있습니다. 그 사람의 그림의 버릇 같은 것도 학습시킬 수 있기 때문에, 자신의 화풍을 재현시키는 LoRA를 낳을 수도 있습니다.

CoppyLora_webUI 설정 화면. 참고 화면(위)을 필자가 모사한 것을 copainter로 펜 넣어 학습용 데이터(아래)로 했다. 아래의 화풍을 계승한 선화 LoRA를 만들 수 있다
생성한 Lora를 사용해, 이미지를 랜덤인 프롬프트로 생성해 본 것. 필자가 준비한 이미지의 버릇이 LoRA를 통해 반영되고 있다. 특히 눈이나 머리에 나오는어쨌든 그림 그리기 소프트웨어와 수정 소프트웨어에
copainter는 복사기 LoRA 학습법과 같은 기술을 사용하여 튜닝을 실시해 갔다고 생각됩니다. 선화를 추출하는 특수기능 LoRA와 착채용 특수기능 LoRA를 개발하여 이미지의 흑백화와 노이즈를 없애는 등의 부차적인 처리도 추가되어 품질이 높은 아웃풋을 낼 수 있는 서비스 실현 있을 것입니다.copainter 개발자의 마쿠스씨는 X로, 보다 러프한 그림에서도, 프롬프트 입력과 조합하는 것으로 출력 가능하게 하는 기능을 추가한다고 코멘트하고 있습니다. 이미지 생성 AI는 보완이 되는 텍스트 프롬프트가 추가됨으로써 보다 정확하게 대상물을 묘사해 줄 확률이 높아지므로 효과는 큰 것으로 생각됩니다.
copainter는, 인간이 일러스트를 그리는 작업의 보조 수단으로서 사용하기 쉬운, 생성 AI계의 웹 서비스로서 등장했습니다. 현재 copainter는 단기능입니다만, 다기능화를 진행하면서, 어느 쪽은 그림 그리기계 소프트나 리터치계 소프트에 짜넣어져 가는 것이 아닐까 미래의 발전을 기대할 수 있습니다.
-
에
 A admin님이 에서 이 토픽을 이동함
A admin님이 에서 이 토픽을 이동함
-
에A admin님이 자유게시판에서 이 토픽을 이동함
-
에A admin님이 에서 이 토픽을 이동함
-
에A admin님이 자유게시판에서 이 토픽을 이동함
-
에A admin님이 만화에서 이 토픽을 이동함