


0
온라인133
사용자22.0k
토픽22.2k
게시물
-
SPAR3D는 단일 이미지에서 3D 메시를 재구성하는 최첨단 방법입니다. 이 데모에서는 이미지를 업로드하고 이를 통해 3D 메시 모델을 생성할 수 있습니다. SPAR3D의 특징은 메시를 생성하기 전에 중간 표현으로 포인트 클라우드를 생성한다는 것입니다. 포인트 클라우드를 편집하여 최종 메시를 조정할 수 있습니다. 이 데모에서는 포인트 클라우드를 드래그, 색상 변경 및 크기 조정이 가능한 간단한 포인트 클라우드 편집기를 제공합니다. 보다 고급 편집이 필요한 경우(예: 상자 선택, 복제, 로컬 스트레칭 등) 포인트 클라우드를 다운로드하여 MeshLab 또는 Blender와 같은 소프트웨어에서 편집할 수 있습니다. 편집된 포인트 클라우드를 이 데모에 업로드하여 "포인트 클라우드 업로드" 상자를 체크하면 새 3D 모델을 생성할 수 있습니다.
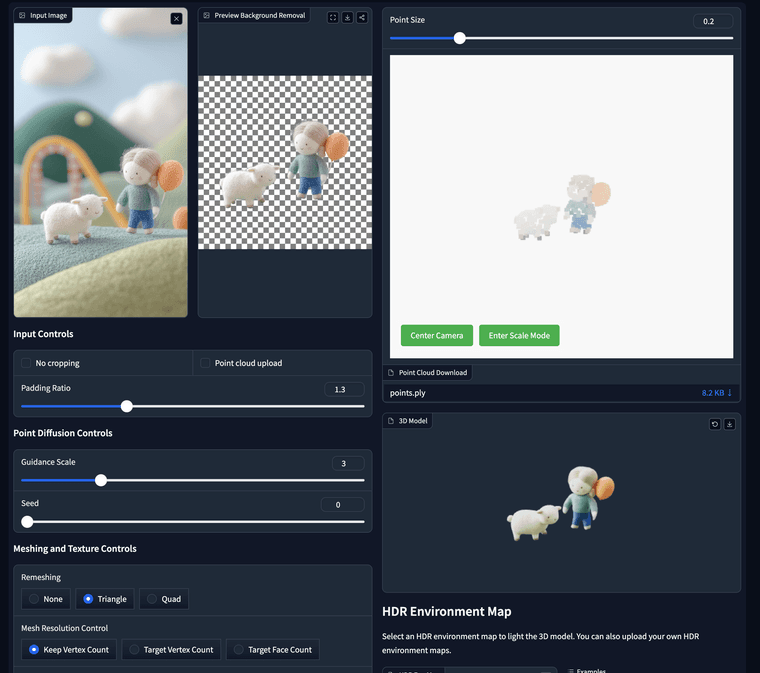
https://huggingface.co/spaces/stabilityai/stable-point-aware-3d
팁
이미지에 유효한 알파 채널이 없으면 배경 제거 단계를 거칩니다. 기본 제공 배경 제거 기능이 부정확할 수 있으며, 이로 인해 메시 품질이 나빠질 수 있습니다. 이런 경우 외부 배경 제거 도구를 사용하여 여기에 업로드하기 전에 RGBA 이미지를 얻을 수 있습니다.
전경 비율을 조정하여 전경 개체의 크기를 제어할 수 있습니다. 이는 최종 메시에 큰 영향을 미칠 수 있습니다.
안내 스케일은 포인트 클라우드 생성 프로세스에서 이미지 조건의 강도를 제어합니다. 값이 높을수록 메시 충실도가 높아질 수 있지만 랜덤 시드를 변경하여 변동성이 낮아집니다. 안내 스케일과 시드는 포인트 클라우드를 수동으로 업로드할 때 효과적이지 않습니다.
온라인 편집기는 Shift 키를 누른 채로 다중 선택을 지원합니다. 이를 통해 여러 점을 한 번에 다시 칠할 수 있습니다.
편집은 주로 개체의 보이지 않는 부분을 변경해야 합니다. 보이는 부분은 편집할 수 있지만 편집 내용은 이미지와 일치해야 합니다. 이미지와 모순되는 방식으로 보이는 부분을 편집하면 메시 품질이 나빠질 수 있습니다.
3D 모델에 조명을 비추기 위해 나만의 HDR 환경 맵을 업로드할 수 있습니다.여기에 태그를 입력하세요. 각 태그는 3에서 15자 사이여야 합니다.
-
에
 A admin님이 자유게시판에서 이 토픽을 이동함
A admin님이 자유게시판에서 이 토픽을 이동함
-
에A admin님이 에서 이 토픽을 이동함